
In his third principle, Dr Edwards William Deming was warning all of us about the risks of mass inspection while stressing about the importance of building quality directly into the product. Today, we’ve learned that the same principle from lean manufacturing can be applied to knowledge work and information technology, where the role of assembly factory lines is assimilated by automation, declarative configuration, infrastructure as code, continuous integration and delivery pipelines.
Some like to call it DevOps, some call it DevSecOps, Lean, Agile, Digital Transformation, or a mix of them. The term is not relevant. What is relevant is something much deeper: it is the cultural stratum, with its values and principles, that generates ideas that lead to actions. The same culture then continuously triggers feedback to validate and question not only those actions, but the existing mindset that nurtured them, pushing it out of the comfort zone with the goal to learn and grow.
This is the context that enabled us to start a multi-year improvement journey where automated CI/CD pipelines help us systematically improve the quality and the security of the software that we write.
And this path we’ve been paving at EDB has been forged with the goal of shifting security to the left of the container-based software distribution process—for PostgreSQL on Kubernetes—thanks to Kubernetes.
Although Deming was referring to quality, the same principle is valid for security as well: security cannot be an activity performed as a downstream stage, before the release, or by a separate department or team. Security is everyone’s responsibility, and should be pervasive in the process and adopted at all stages of the life cycle—from the developer’s conception to the distribution of the software in a containerized form. Specifically in our case, the Cloud Native PostgreSQL pipeline.
As you already know, Kubernetes has been designed with security in mind, through a multi-layered model approach known as “4C”, inspired by the Defense in Depth (DiD) model. The 4C security model for Cloud Native computing with containers is organized in four layers:
- Cloud
- Cluster
- Container
- Code
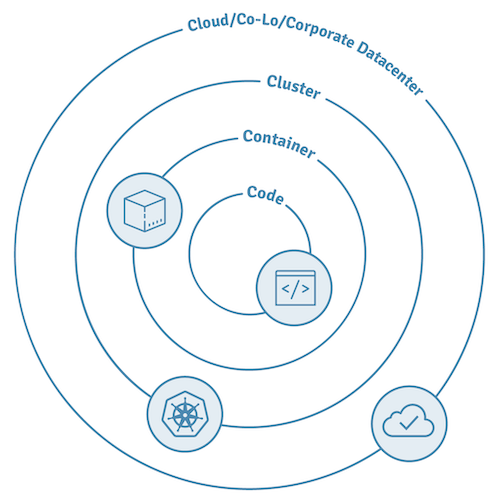
Each layer is shielded by the surrounding layer and provides its own capabilities and features for security.
The Cloud layer is the most external one—and as such, it is the most critical of all in an infrastructure. However, it is out of scope for this article. Similarly, the Cluster layer is specific to a Kubernetes deployment use case and the workloads that run in it.
The remaining two layers, Code and Container, are the ones where those who write software for Kubernetes must operate in order to build quality-in and shift security to the left of the production pipeline.
This article describes our story: how and what we did to build our PostgreSQL operator and operand containers for Kubernetes.
Security at code layer
“You build it, you own it” is a DevOps mantra. Code starts from developers, who must own the process in its entirety and be responsible from the moment they push their “commit” to the time their work generates value for the customer, by meeting their expectations—and possibly beyond. When developers have skin in the game, building quality in and shifting security to the left becomes muscle memory.
What is different now from a decade or two ago is that software development has been analysed and studied carefully, especially when failing.
In their book “Accelerate”, the authors Forsgren, Humble and Kim highlight the key capabilities to improve software delivery, such as version control, automated deployment, continuous integration, trunk-based development, test automation, shift left on security and, last but not least, the ultimate goal of all: continuous delivery.
Based on my experience, continuous delivery is an often misunderstood concept. I like to picture it as nothing more than a contract that all members of a product team—and possibly an organization—abide by and which makes sure that the latest version on the trunk is the most stable version ever and is ready to be deployed in production at any time.
Doesn’t this simple concept, which requires all the previous capabilities, imply quality and security? The volatility, uncertainty, complexity and ambiguity that are intrinsic in innovative technology and knowledge work cannot prescind from teamwork.
As a result, we have adopted the Github flow and configured our Github repositories to require at least two peer reviews before the patch can be considered suitable for merging on the trunk (the “main” protected branch).
With the right culture and a psychologically safe environment, such a process increases the chances to find defects and security issues at an early stage of the process, through pair programming, constructive dissent, feedback and dialogue within the team. It gets better and more robust with CI/CD pipelines, the automated backbones that create an end to end flow between the development team and the final user of a product and that goes through the entire organization.
At EDB, we rely on Github actions and, among the others, we run unit tests as well as linters for static code analysis and security scanning to catch defects and known vulnerabilities immediately after a commit is pushed.
Thanks to Github flow and Github actions settings, we have configured a system that prevents any patch from landing on trunk if the pipeline run fails (remember continuous delivery?).
Once we’ve done our best with the code, it is time to move to the next level, the container.
Security at the container layer
Once the code has been checked, it needs to be “packaged” as a container image to run in Kubernetes. We have chosen to rely on RedHat Universal Base Images (UBI), but you can choose different base images.
Our advice is to build such containers following the immutable application container paradigm, requiring a single PID 1 entrypoint process that doesn’t need any root privilege.
The resulting container images can be scanned for known vulnerabilities and exposures, as well as for compliance with some security best practices.
Our container image pipelines run a linter called Dockle to scan the image and ensure, for example, that the container does not run as root or enable sudo execution.
A container should be designed and built to run an application that can exclusively access the information and the resources that are needed to achieve its goals. In Information Technology, this is known as the principle of least privilege (PoLP) – sometimes also referred to as the principle of least authority (PoLA).
As a result, containers in Kubernetes should run as unprivileged users, unless otherwise required. This is extremely important from a security point of view as it prevents at the source any privilege escalation attempt originating inside the container to gain control of the outer host machine.
The images are also scanned by Clair once they are pushed on the Quay.io container registries. Additionally, once a day we automatically rebuild the container images and release a patch level version in case Clair detects any known vulnerabilities and fixes are available.
The diagram below illustrates the pipeline to build on a daily basis and distribute the container images for PostgreSQL.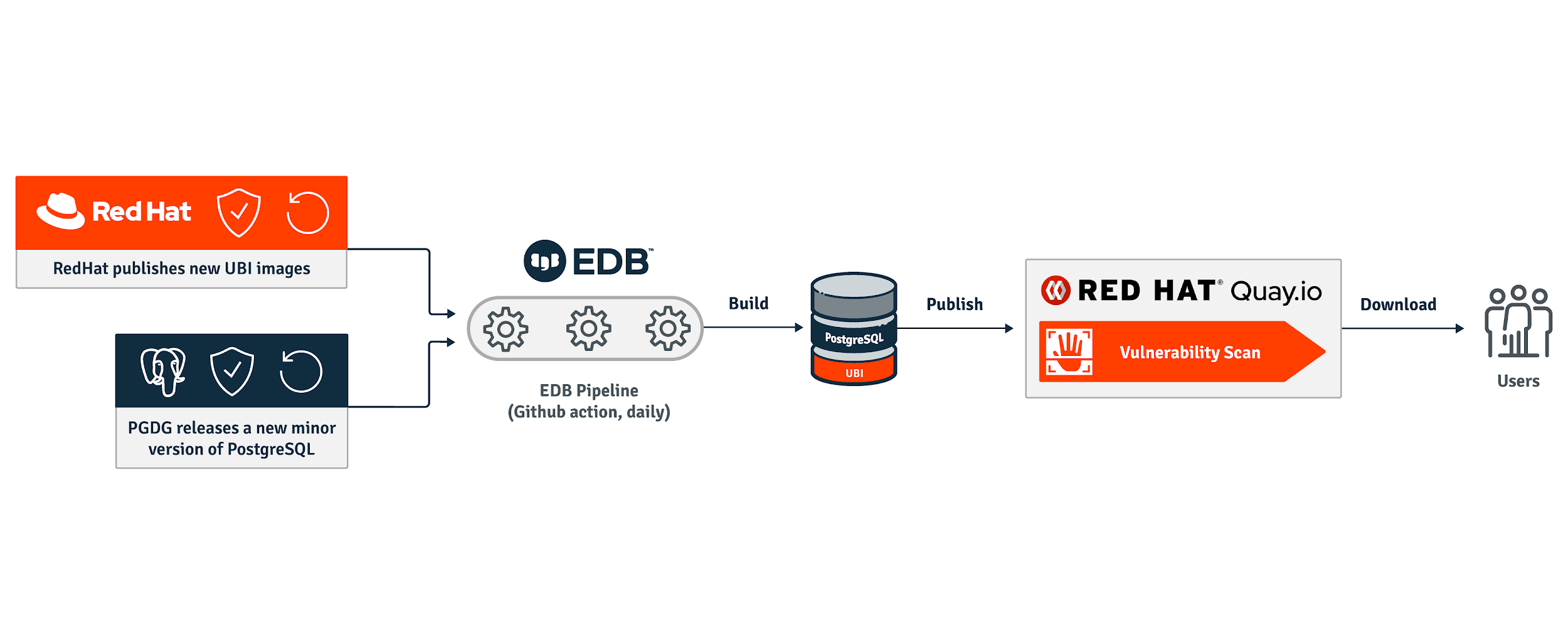
Leveraging Kubernetes for pipelines
Once the images have passed all these security checks and snapshot images are available, developers can really start leveraging containers and Kubernetes for end to end (E2) testing of applications in distributed systems.
This means that we can rely on ad-hoc Kubernetes clusters that exist for the sole duration of the tests and that can run and integrate all the software that is related to a product and, specifically, a product build.
Let me clarify this generic concept with an example that is related to our specific experience to bring PostgreSQL on Kubernetes through an operator.
Everytime a new patch is committed for the operator in a development branch and pushed to the Github repository, Github actions trigger linters, run unit tests, build the images, scan them for the aforementioned vulnerabilities and then start a minimal set of E2E tests. A failure at any level provides immediate negative feedback to the developer, who needs to fix the issues before retrying (this is similar to the andon cord concept in a Toyota assembly line).
Otherwise, in case of success, the developer submits a pull request which then sets in motion the review by two additional developers. They will most likely propose changes and ultimately approve the pull request, initiating a deeper level of automated tests in the pipeline. If they pass, the patch can be squashed and merged on the main branch by an administrator.
As a side note, thanks to the pipelines, we are able to automatically test every patch for the operator on about 45 combinations, using a two dimensional matrix made up by:
-
- All community-supported Kubernetes versions (currently 1.16 and above) using Kubernetes in Docker (kind), as well as OpenShift (4.5, 4.6 and 4.7), AKS, EKS and GKE
- PostgreSQL versions 10, 11, 12 and 13
Kubernetes has incredibly facilitated automated testing of PostgreSQL distributed clusters for events such as failure on the primary and promotion of a replica (failover), backup, recovery, switchovers, scale up/down, rolling upgrades, and so on.
Bringing PostgreSQL to Kubernetes
PostgreSQL is one of the most fascinating and successful open source projects in human history, as well as one of the best databases currently available. It’s not a coincidence that it was named database of the year in 2020 by DB-engines.
Over the last two decades we have been an active part of the growing PostgreSQL community and project, with direct and consistent open source contributions to the code. We have been committed to improve its business continuity capabilities and performance over the years, first on bare metals and then on virtual machines.
Now the time has come for us to bring PostgreSQL to Kubernetes as well, following the DevOps values, principles and methods described above, and leveraging containers and Kubernetes to build quality in the product and shifting left on security.
Feel free to look at how we build the operand container images for PostgreSQL in our repository on Github, as well as to test the Cloud Native PostgreSQL operator.
Join the cloud native community at KubeCon + CloudNativeCon Europe 2021 – Virtual from May 4-7 to further the education and advancement of cloud native computing.





